
7月15日,北京——Graphcore今日正式发布第二代IPU以及用于大规模系统级产品IPU-Machine: M2000(IPU-M2000),新一代产品具有更强的处理能力、更多的内存和内置的可扩展性,可处理极其庞大的机器智能工作负载。
IPU-M2000是一款即插即用的机器智能刀片式计算单元,由Graphcore全新的7纳米 Colossus™ 第二代 GC200 IPU提供动力,并由Poplar™软件栈提供全面支持。其设计便于部署,并支持可扩展至大规模的系统。这款纤薄的1U刀片机可提供1个PetaFlop的机器智能计算,并集成了针对AI扩展优化的网络技术。

*Graphcore第二代Colossus™ IPU处理器:GC200

*Graphcore IPU-M2000
IPU-M2000可构建成IPU-POD64这一Graphcore全新模块化机架规模解决方案,可用于极大型机器智能横向扩展,提供前所未有的AI计算可能性,以及完全的灵活性和易于部署的特性。它可以从一个机架式本地系统扩展到高度互连的超高性能AI计算设施中的1000多个IPU-POD64系统。
“随着IPU-M2000和IPU-POD64的推出,Graphcore进一步扩大了我们在机器智能领域的产品竞争优势。”Graphcore首席执行官Nigel Toon指出:“Graphcore通过技术创新实现更强有力的产品线,这些创新能够提供客户所期望的行业领先性能。对于寻求将机器智能计算添加到数据中心的客户而言,Graphcore最新推出的IPU-M2000凭借其强大的算力、易于扩展的灵活性和突出的易用性,将具有极强的可行性和价值提升潜力。”
Mk1 IPU产品的用户可以确信,他们现有的模型和系统可以在这些新的Mk2 IPU系统上无缝运行。虽然第一代Graphcore IPU产品已经处于领先地位,但与之相比,第二代产品的性能还将提高8倍。
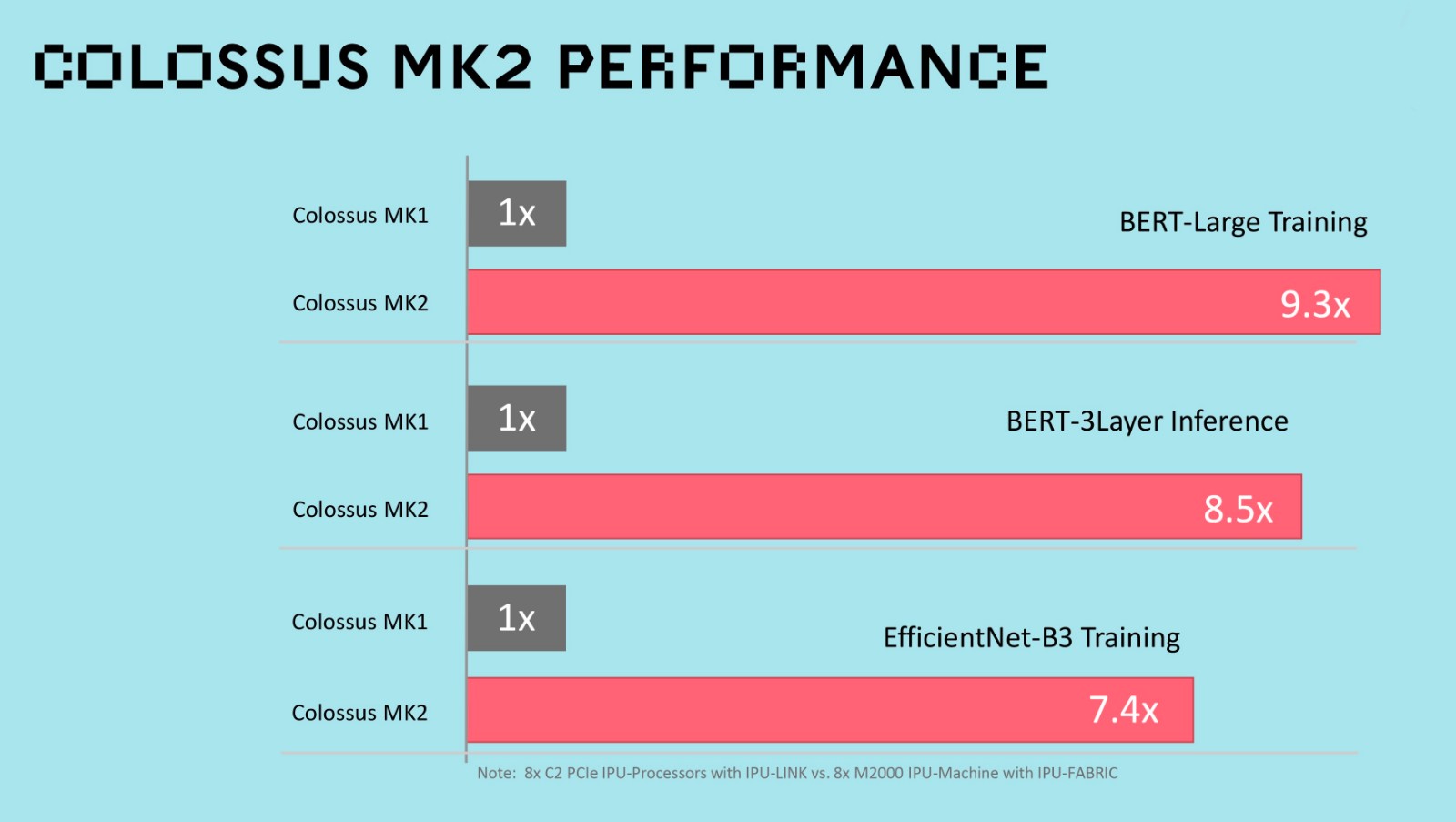
*Mk1 IPU产品与Mk2 IPU产品性能对比
IPU-M2000的设计使客户可以在IPU-POD™配置中构建多达64,000个IPU的数据中心规模系统,提供16ExaFlops的机器智能计算能力。新的IPU-M2000甚至能够处理最艰巨的机器智能训练或大规模部署工作负载。
Graphcore全新的IPU-Fabric™技术使大规模连接IPU-M2000和IPU-POD成为可能,该技术是专为机器智能通信而从头设计的,并提供了专用的低时延结构,可在整个数据中心内连接IPU。
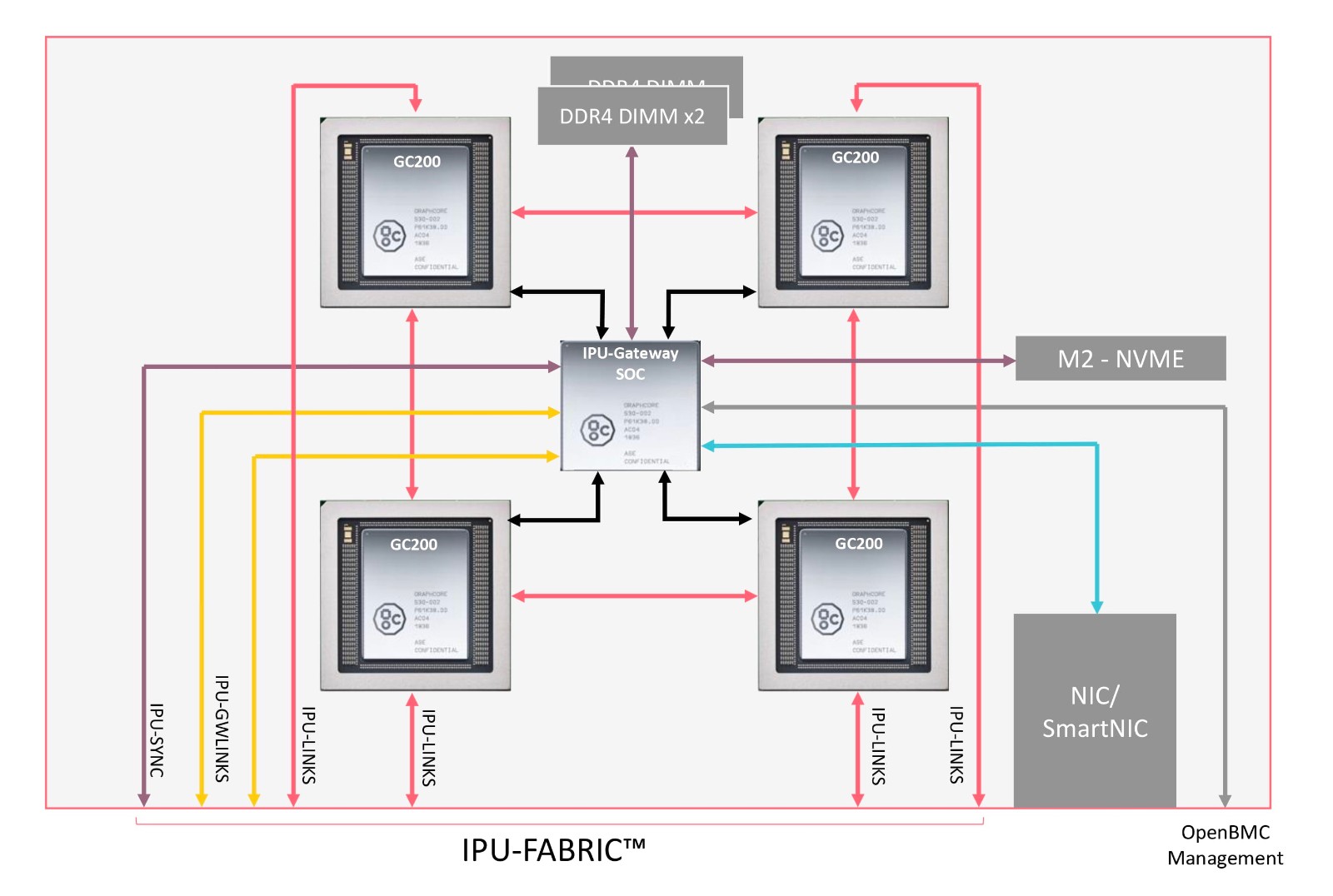
*Graphcore IPU-Fabric™技术
Graphcore的Virtual-IPU软件与工作量管理和编排软件集成在一起,可以轻松地为许多不同的用户提供训练和推理服务,并允许根据工作情况调整和重新配置可用的资源。
无论您是要使用单个IPU还是要使用数千个IPU来完成机器智能工作负载,Graphcore的Poplar SDK都可以使这一过程变得简单。您可以使用首选的AI框架(例如TensorFlow或PyTorch)。而且,从这一高级描述中,Poplar将构建完整的计算图,以捕获计算、数据和通信。然后,它会充分利用可用的IPU硬件,编译此计算图,并构建用于管理计算、存储和网络通信的运行时程序。
Graphcore的最新产品线是通过三大颠覆性技术创新实现的,这些创新可提供客户期望的行业领先性能:
· 计算:每个IPU-M2000的核心都是Graphcore新的Graphcore Colossus™Mk2 GC200 IPU。该芯片采用台积电最新的7纳米工艺技术开发,每个芯片在一个823平方毫米的裸片上包含超过594亿个晶体管,使其成为有史以来最复杂的处理器。
· 数据:每个IPU都有大量的In-Processor Memory™。Graphcore新型Mk2 GC200在处理器内部具有史无前例的900MB超高速SRAM,在每个处理器内核旁边都设有大量RAM,以实现每位最低能量的访问。Graphcore的Poplar软件还允许IPU通过Graphcore独特的Exchange-Memory™通信访问Streaming Memory™。这甚至可以支持具有数千亿个参数的最大模型。每个IPU-M2000都可以支持密度高达450GB的Exchange-Memory™,以及前所未有的180TB/秒的带宽。
· 通信:IPU-M2000具有内置的专用AI联网IPU-Fabric™。Graphcore创建了一个新的Graphcore GC4000 IPU-Gateway芯片,该芯片可提供令人难以置信的低时延和高带宽,每个IPU-M2000均可提供2.8Tbps。在从数十个IPU扩展到数以万计个IPU的过程中,IPU-Fabric技术使通信时延几乎保持恒定。
“将强劲算力与网络能力相结合,我们能够处理全球最先进、最复杂的算法模型。”Graphcore高级副总裁兼中国区总经理卢涛表示:“这样的算法模型,对中国本地的AI算法落地场景,如云计算、互联网和通信等场景都会产生推动作用,并将为AI产业者提供巨大的价值。”
在中国市场,Graphcore与领先的本地商业用户展开紧密的早期合作,基于IPU的开发者云已于7月初正式上线,其IPU-POD产品技术,已在IPU开发者云上供用户访问。因此,中国很可能成为Graphcore最新推出的第二代处理器技术最先实现商业化落地的区域之一。

x

-
 永不断电?这次马斯克想把你家变成“发电厂” 2021-05-08 10:54
永不断电?这次马斯克想把你家变成“发电厂” 2021-05-08 10:54 -
 上海车展落幕,一场智能汽车逆袭传统汽车的大戏 2021-04-28 16:53
上海车展落幕,一场智能汽车逆袭传统汽车的大戏 2021-04-28 16:53 -
 左手DRIVE Orin,右手DRIVE Atlan,黄仁勋靠自动驾驶芯片狂赚80亿美元 2021-04-13 16:56
左手DRIVE Orin,右手DRIVE Atlan,黄仁勋靠自动驾驶芯片狂赚80亿美元 2021-04-13 16:56
-
 英特尔宣布成立全新独立运营的FPGA公司——Altera 2024-03-01 12:47
英特尔宣布成立全新独立运营的FPGA公司——Altera 2024-03-01 12:47 -
 哪吒汽车 All In AI,携手360集团推进大模型产品NETA GPT 上车 2024-03-01 17:21
哪吒汽车 All In AI,携手360集团推进大模型产品NETA GPT 上车 2024-03-01 17:21 -
 15万有骁龙8295,16万配激光雷达,零跑C10发起“配置战” 2024-03-03 14:00
15万有骁龙8295,16万配激光雷达,零跑C10发起“配置战” 2024-03-03 14:00

 京公网安备 11010502038466号
京公网安备 11010502038466号

 关注官方微信
关注官方微信
